
Why traditional link building doesn't move AI citations — and what does
Across 60 prompts in 3 industries on our own GEO Graph index, plus a converging body of independent industry analysis, one pattern keeps showing up: AI citation likelihood is gated by entity recognizability across knowledge graphs, not by backlink volume on your own domain. Backlinks still matter for Google ranking, which feeds AI Overviews indirectly. But ChatGPT, Perplexity, and Claude don't follow links to decide who to cite — they resolve entities first. This piece walks through the mechanism, the numbers, and the practical sequence that comes out of it.
Methodology
Between March and May 2026, we ran 60 unique prompts across three industries — Angel Investing & Syndicates, B2B SaaS Sales & CRM, and Generative Engine Optimization — through ChatGPT, Perplexity, Claude, and Gemini, capturing every cited source from each engine's citation panel. The 948 individual citations that resulted are the basis for the within-industry numbers cited below.
For broader claims — Wikipedia's share of top-10 ChatGPT sources, third-party domain dominance, Reddit / YouTube growth — we relied on independent industry analyses (Indig, Semrush, Ahrefs, AirOps, Lantern, Muck Rack, Tinuiti, Princeton's GEO paper) listed at the bottom of this post. Vendor-self-published "Nx lift" claims with no documented methodology were excluded.
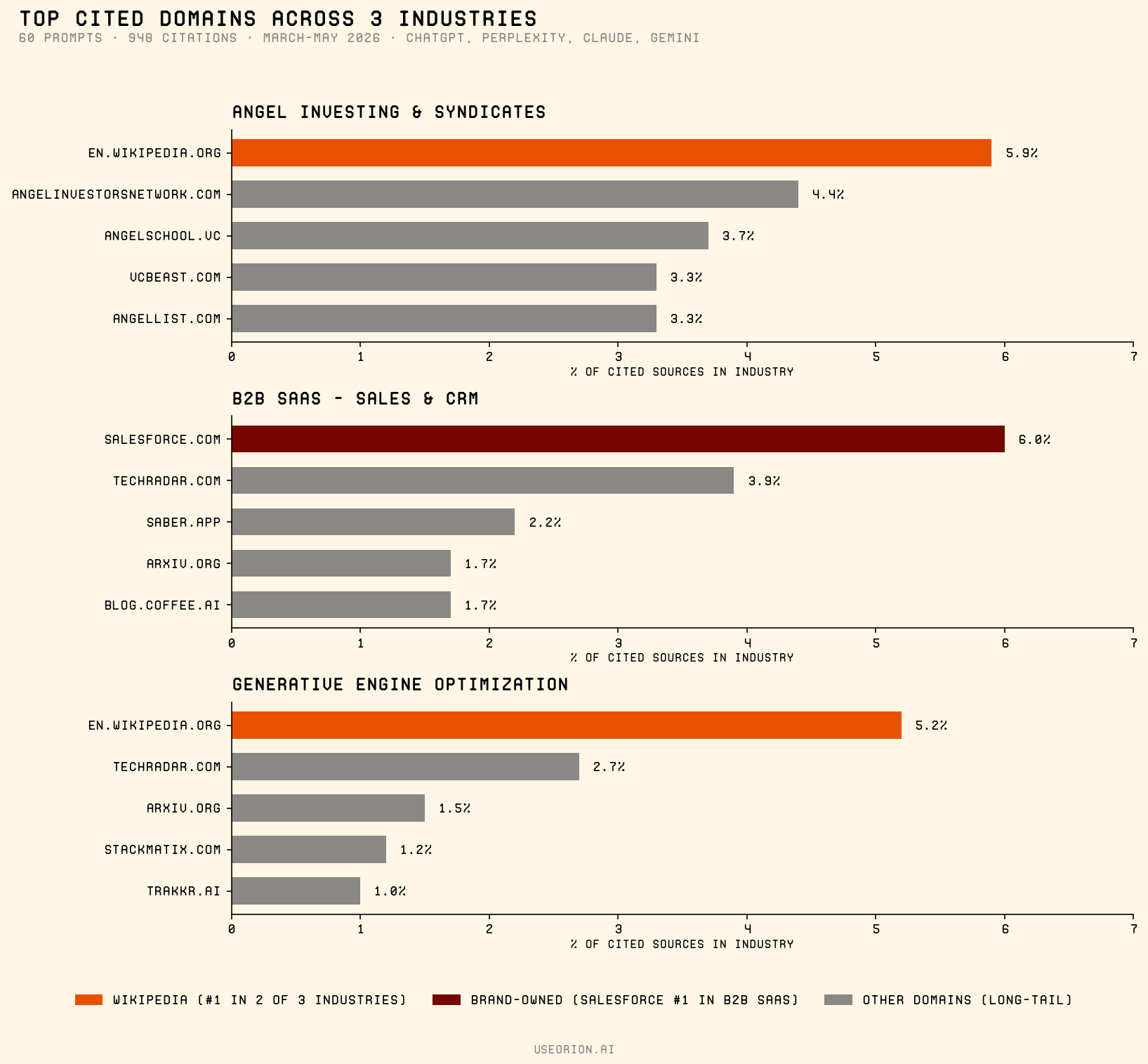
The pattern: Wikipedia is the most consistently cited source — at every scale
Across our three industries, Wikipedia was the #1 cited domain in 2 of 3 and a top-3 source in the third:
- **Angel Investing & Syndicates** — Wikipedia 5.9% of citations (top of a 240-domain long tail)
- **Generative Engine Optimization** — Wikipedia 6.4% combined (en + fr) (the #1 domain across 408 distinct sources cited)
- **B2B SaaS Sales & CRM** — Salesforce.com 6.0% (#1, beating Wikipedia at 1.1%); the only industry where a single vendor's own domain dominated, presumably because Salesforce *is* the canonical entity for "sales & CRM" in the AI's training data
Zoom out and the pattern intensifies. Kevin Indig's analysis of ~1.2 million ChatGPT responses (~98K citations) found that Wikipedia accounts for 47.9% of ChatGPT's top-10 cited sources (Search Engine Land). Semrush's most-cited-domains study found Reddit alone accounts for 40.1% of LLM citations and 46.7% of Perplexity citations (Semrush).
Different studies, different sample sizes, same shape: a small handful of cross-source authority domains dominate the top of every distribution, and the long tail under them is enormous.
The temptation is to read this as "Wikipedia is high-authority content, so AI prefers high-authority content." That's the wrong takeaway.
What's actually happening: entity resolution, not content ranking
When you ask ChatGPT "what's the best [category]?", the model isn't crawling and ranking pages the way Google does. It's running a different process first.
It needs to disambiguate the entities involved.
Take a token like "Orion." That string could mean:
- the constellation
- NASA's Artemis crew spacecraft
- a SaaS company in GEO/AI search
- a boutique hotel chain
- dozens of other distinct entities
Before the model can answer "what's the best AI visibility platform like Orion?", it needs to pin "Orion" to a specific, canonical entity. The way it does that is via structured knowledge graphs — Wikidata, Wikipedia, Crunchbase, LinkedIn, G2 — where entities have unique identifiers, descriptions, and cross-source relationships.
Brands that don't exist consistently across those graphs face a binary problem: the model can't pin them to anything specific, so they don't get included in the answer. Not because the content is bad. Because the entity is ambiguous.
The independent evidence converges on this from several angles:
- **Lantern's 200M-citation analysis** found **91% of AI brand citations come from external sources** (not the brand's own domain), with G2 / Capterra / TrustRadius alone driving 44% of those external citations ([Lantern](https://www.asklantern.com/blogs/91-of-ai-citations-ignore-your-website)).
- **AirOps's 2026 State of AI Search report** found **85% of brand mentions originate from third-party pages** rather than owned domains, with 48% of citations coming from community platforms like Reddit and YouTube ([AirOps](https://www.airops.com/report/the-2026-state-of-ai-search)).
- **Muck Rack's analysis of 25M+ links** across ChatGPT, Claude, and Gemini found earned media accounts for **84% of all AI citations** ([Muck Rack via MarTech Series](https://martechseries.com/content/generative-pulse-earned-media-consistently-drives-ai-citations-holding-at-84/)).
- **Foundation Marketing's analysis of 57M AI citations** found brand-owned pages accounted for only 10% ([Foundation Marketing × AirOps](https://foundationinc.co/lab/foundation-marketing-airops-report)).
The same finding from different angles
Citation likelihood is gated by entity recognizability and cross-source agreement, not by what's on your own domain. Lantern, AirOps, Muck Rack, and Foundation Marketing converge on this from four different methodologies and sample sizes — each independently arriving at "~85-91% of AI citations come from somewhere other than the brand's own site."
Why your existing backlinks aren't moving the needle directly
This isn't to say backlinks are dead. They still do work — for Google's traditional ranking, which feeds AI Overviews indirectly. A page with strong backlinks is more likely to be in the corpus AI engines see at all.
But the citation decision itself happens later, at entity resolution time. And entity resolution doesn't read backlinks. It reads cross-source agreement:
- Does Wikidata describe this brand with this description?
- Does Crunchbase agree on the same description?
- Does LinkedIn confirm the company name and industry?
- Does the website's structured data match?
When those agree, the entity resolves cleanly and the brand becomes a citation candidate. When they don't, the entity is ambiguous and the brand silently drops out of the answer.
This is why two brands with similar SEO profiles can get completely different AI citation rates. The one with consistent, structured presence across Wikipedia / Wikidata / Crunchbase / G2 / LinkedIn gets cited. The one without disappears — even if its content is better.
What actually moves AI citations
Ranked by independent evidence quality:
1. Cross-source entity consistency. Same canonical name, same description, same domain across Wikidata, Crunchbase, LinkedIn, G2 / Capterra. This is the foundation. Skip it and nothing else in this list compounds.
2. Review-platform presence (B2B specifically). Lantern's 200M-citation study identified G2, Capterra, and TrustRadius as the three review platforms driving 44% of all external brand citations in AI search. For B2B SaaS, this is the highest-leverage move after entity consistency.
3. High-karma authoritative Reddit answers in your category. Semrush found Reddit accounts for 40.1% of LLM citations and 46.7% of Perplexity citations. Tinuiti's Q1 2026 report tracked a +73% share growth in the technology category alone (Tinuiti). LLMs treat highly-upvoted, long-form Reddit answers as authoritative because the karma signal is hard to fake at scale.
4. YouTube content with full transcripts. Ahrefs's 75,000-brand study found mentions in YouTube titles and transcripts is the single strongest correlator with AI Overview visibility (correlation coefficient ~0.737, beating every other input including backlinks) (Ahrefs).
5. Earned media on AI-indexed outlets. Muck Rack's 84%-from-earned-media finding becomes actionable here. Search Engine Land, Search Engine Journal, Built In, Yahoo Finance /news/ are confirmed AI citation sources.
6. Original-research, stat-rich content. Princeton's GEO paper found GEO methods improve visibility by up to 40% in generative engine responses, with statistics addition and quotation addition outperforming most other techniques (arxiv 2311.09735). Original numbers with clear attribution beat opinion pieces consistently.
Notice what's *not* on this list: your backlink profile, your domain authority score, your keyword density. These are still part of the foundation — every brand needs them to compete in search at all — but they're the floor, not the lever. They help Google ranking and reach AI Overviews indirectly. To directly move ChatGPT, Perplexity, or Claude citations, you need the six factors above.
What this changes about the SEO playbook
If you're an SEO or marketing team trying to be visible to AI engines, the practical sequence shifts:
- **Audit your entity presence first** — not your rankings. Wikidata, Crunchbase, LinkedIn, G2, Wikipedia. Are they all describing the same company with the same name and the same domain? If not, fix that before you do anything else. It's the cheapest, fastest, longest-half-life work in the playbook. (You can run a free GEO audit on your own domain at [useorion.ai](https://useorion.ai/signup?utm_source=blog&utm_medium=organic&utm_campaign=link-building-ai-citations) — it scores entity-presence factors and tells you what to fix first.)
- **Treat third-party platforms as the placement layer.** Reddit answers, YouTube transcripts, contributor articles in industry outlets, G2/Capterra reviews. These are where AI engines find you — not your homepage.
- **Use structured data and quick-answer blocks on the pages you do own.** This still helps — but as a *parsing-readability layer* on top of an entity that AI engines already recognize. Not as a substitute for the entity work.
Backlink campaigns in this world are an indirect lever. They're not bad — they help your Google performance, which has spillover effects. But if you're optimizing for AI citation specifically, you'll get more output from a single accurate Wikidata item, three high-karma Reddit answers, and one corrected Crunchbase profile than from another quarter of link building.
An open question
We'd be curious whether the Wikipedia-dominance pattern holds in your vertical too. Our 3-industry sample (Angel Investing, B2B SaaS Sales/CRM, GEO/AI Marketing) is narrow enough that the brand-owned dominance we saw in B2B SaaS — Salesforce.com beating Wikipedia — is probably not generalizable. We'd expect retail and B2C to look very different again — more Reddit-weighted, perhaps more TikTok-weighted as that platform's transcripts get indexed.
If you've been tracking AI citations in a different industry and seen something different, we'd want to hear it. The mechanism (entity resolution) should be universal. The platform mix probably isn't.
Frequently Asked Questions
- Do backlinks still help AI citations?
- Indirectly. Backlinks help Google rank your pages, which feeds Google AI Overviews via the Google index. But ChatGPT, Perplexity, and Claude don't follow links to decide who to cite — they resolve entities first using structured knowledge graphs. So backlink campaigns help one channel (Google AIO) and barely move three others (ChatGPT, Perplexity, Claude). For AI-citation-specific work, entity-presence work is higher leverage.
- Why is Wikipedia cited so heavily by AI engines?
- Not because Wikipedia is "high authority content." Because Wikipedia (with Wikidata) is the canonical structured knowledge graph AI engines use for entity resolution. Before answering "what's the best X?", the model needs to pin every brand mentioned to a unique entity. Wikipedia provides that mapping for tens of millions of entities. Brands that exist on Wikipedia/Wikidata are easier to resolve and therefore easier to cite. The 47.9% top-10 ChatGPT share Indig found is downstream of that mechanism, not upstream.
- If we're a B2B SaaS company, what's the highest-leverage move?
- Review-platform presence on G2, Capterra, and TrustRadius. Lantern's 200M-citation study found those three platforms drive 44% of all external brand citations in AI search. For B2B SaaS specifically — where buyer-intent queries explicitly involve "best [category]" comparisons — review platforms are the canonical source AI engines pull from. Get on them, get verified, encourage real reviews from customers.
- Do I need a Wikipedia page to get cited by AI?
- Not always. Wikidata (the structured-data layer that powers Wikipedia entries) is more important than the Wikipedia article itself. Many brands have Wikidata items without Wikipedia articles, and those Wikidata items are usable by AI engines for entity resolution. Getting on Wikipedia requires meeting WP:N notability standards, which most early-stage brands don't yet — but Wikidata has a lower bar and is independently valuable.
- How does this apply to local businesses or B2C brands?
- We don't have direct data on those verticals — our 3-industry sample (Angel Investing, B2B SaaS, GEO) is B2B-skewed. We'd expect retail and B2C to be more Reddit- and YouTube-weighted, with Wikipedia mattering less and review platforms (Yelp, Trustpilot) mattering more. The mechanism (entity resolution) should still apply — the platform mix is what changes by vertical.
See where your brand resolves — and where it doesn't.
The free Day 1 audit on Orion checks your domain across the entity-presence factors above (Wikidata, Crunchbase, LinkedIn, G2, schema agreement) and tells you exactly what to fix first. Takes 3 minutes, no credit card.
Run your free GEO auditKeep reading
Best LLMs.txt examples for SaaS sites
Seven llms.txt files from B2B SaaS sites fetched directly in June 2026 — Orion, Stripe, Vercel, Curs...
Best 5 AEO platforms for B2B SaaS in 2026
We compared the 5 Answer Engine Optimization platforms B2B SaaS teams actually evaluate in 2026 — wi...
Fix #1: Why the First 40 Words of Your Page Decide Whether AI Cites You
87% of audited pages bury the answer past word 200. AI engines never read that far. Fix #1 of the 30...